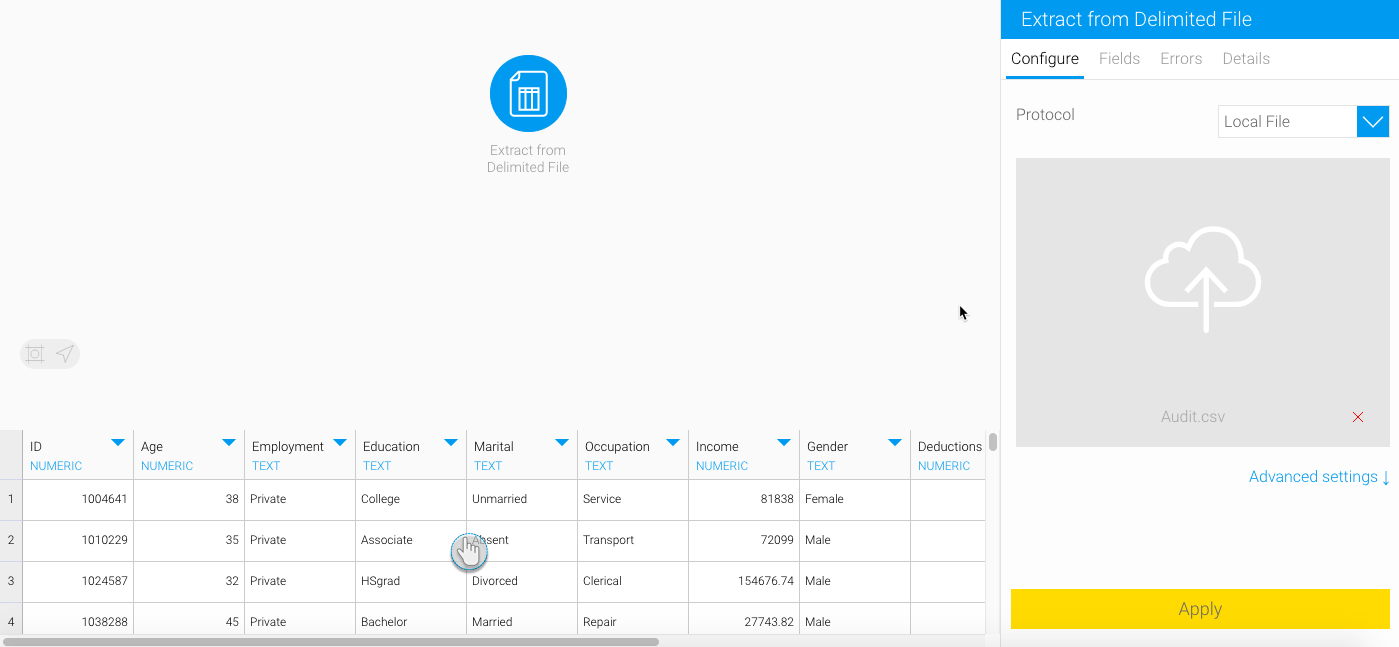
This input method is used when extracting data from a delimited file (that is, a file with separators).
Step Configuration
Follow the guidelines below to configure a delimited file step:
- Click on the Input Steps button on the left side of the Transformation Flow builder, to view a panel will all the input steps.
- Drag the Delimited File option from this panel.
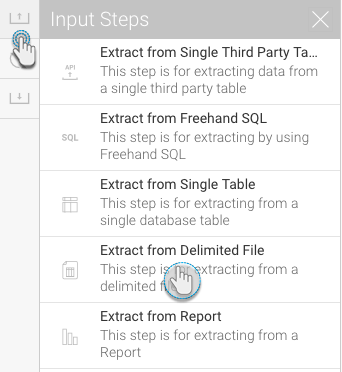
Configure the step to extract data from the file. First select the file protocol.
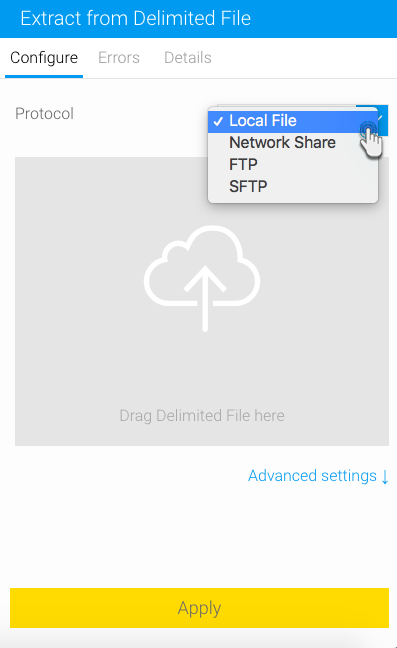
If the file to be imported is available locally, choose the Local option and drag it into the specified area (or click on it to browse and select the file).
If you have selected to import a local file, the file should be local on your server.
But to use a file that's available on a network, select the correct protocol (Network Share, FTP, or SFTP), then provide connection details to connect to the network.
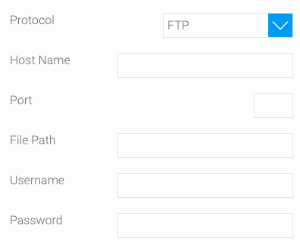
You can also provide additional configuration settings by enabling the Advanced Settings toggle.
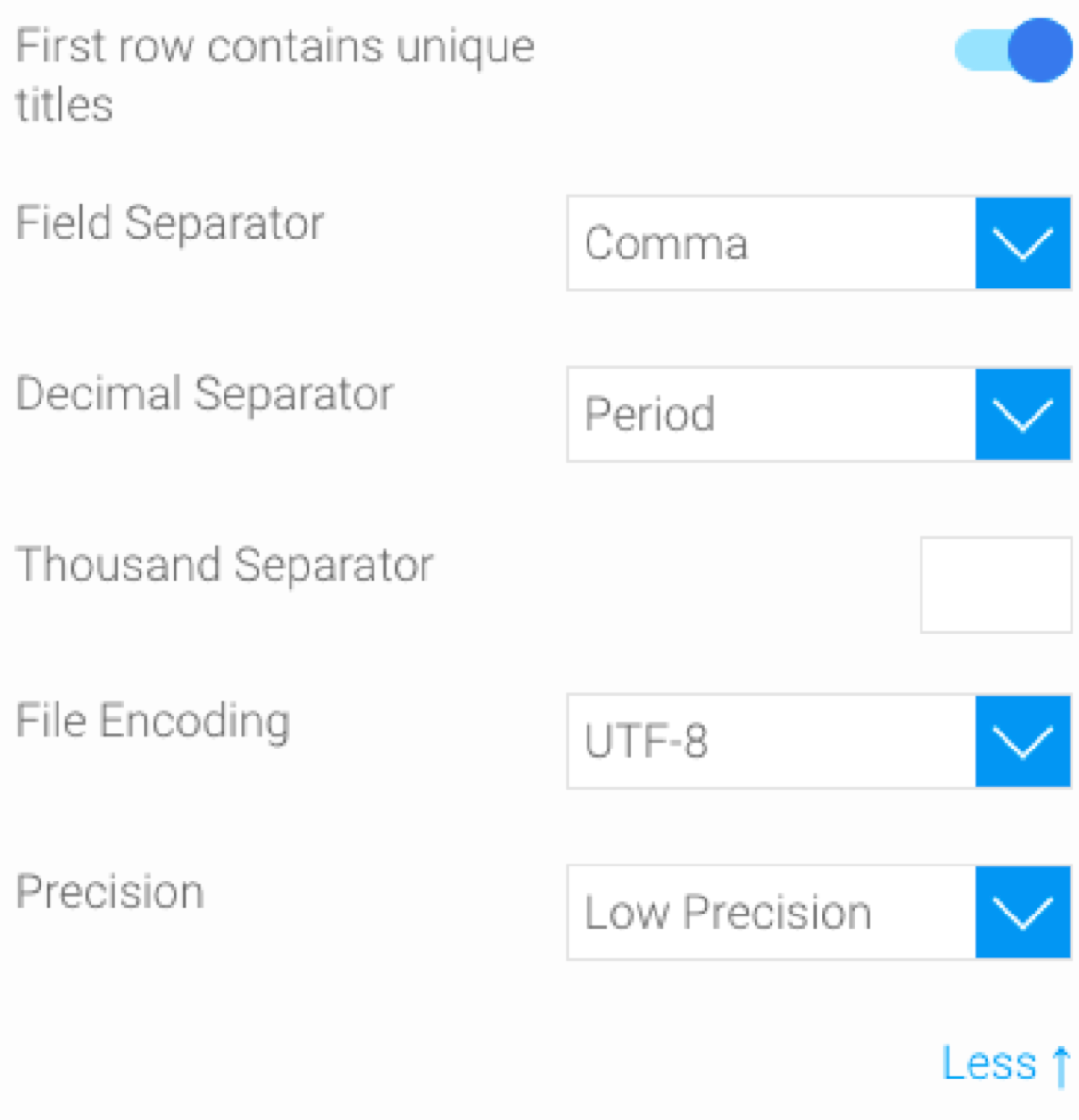
- First row contains unique titles: Enable this toggle switch if the first row of the file contains titles or column names. If switched on, the system will read these values as the column field titles.
- Field separator: Choose a character from the list to use it to separate values in the CSV, or enter a custom one after selecting the Other option.
- Decimal separator: Choose a character from the list to set it as the decimal separator, or enter a custom one after selecting the Other option.
- Thousand Separator: Add a character that the system reads as the thousand separator. Note: If this is not specified, and the field includes values with a thousand separator, then the field would be considered a Text field. Specifying this character, will let the system know that it is a Numeric field.
- File encoding: Select a file encoding option.
- Precision: Use this to specify how many rows of the CVS file Yellowfin will examine in order to define the field types and size.
- Low Precision is fast, and only examines the first 1000 rows of the file.
- High Precision is slower, depending on the size of the file, as it examines all rows.
Finally, click Apply. Data extracted from the file will appear in the data preview panel.